10 Transformer Interview Questions Every AI Engineer Should Know
What is a Transformer?
The Transformer architecture has entirely reinvented AI – both the chatbots and the state-of-the-art models such as GPT and BERT. When you are getting ready to interview AI/ML, you can assume that any interview questions related to transformers will dominate the interview.
These are 10 critical transformer interview questions and clever, well-organized responses.
1️⃣ What is a Transformer in AI, and why did it change the game?
Transformer architecture was introduced in a Research paper named “Attention is all you need ” (2017). It is a deep learning architecture that differs from RNN and CNN by depending entirely on self-attention mechanisms instead of recurrence or convolution.
How it changed the game:
- Allows parallel training, as opposed to sequential RNNs
- Very efficient in handling long-term dependencies
- scalable enough for handling billions of parameters for today’s LLMs
2️⃣ How do Transformers outperform RNNs and CNNs?
RNNs: RNNs are known to handle data sequentially, resulting in slow training and vanishing gradient issues, whereas transformers process data in parallel, making it more efficient.
CNNs: CNNs use feature maps, which help them capture local patterns, but they struggle in handling long dependencies, whereas self-attention in transformers is able to provide the global context in a single step.
3️⃣ Explain the encoder–decoder structure.
Encoder: Consumes input sequence + generates contextual embeddings with self-attention + feed-forward layers.
Decoder: employs masked self-attention (to avoid glimpsing into the future) + cross-attention (to relate to encoder outputs) (yields outputs step-by-step)
4️⃣ What is multi-head attention, and why is it so powerful?
The model has multiple attention heads running in parallel as opposed to calculating a single attention score.
The heads are taught various relationships (e.g., syntactic vs. semantic). Their productions are accumulated → more rich.
👉 Multi-head attention = the model examines input in multiple directions at the same time.
5️⃣ How do residual connections and layer normalization help?
Backward residual connectivity: Rejecting connection between the output of one layer and the input of the same layer (backwards) → vanishing gradients avoided and further training facilitated.
Layer normalization: Does normalization of activations → stabilizes training and accelerates training.
The combination of these makes Transformers scalable to train.
6️⃣ What is self-attention vs cross-attention?
Self-attention: A sequence pays attention to itself → learns internal dependencies (applied in the encoders and decoders).
Cross-attention: Decoder looks at encoder outputs Current: Conjoin the input and the output sequence (indispensable to translation, summarization).
7️⃣ Why do Transformers need positional encoding?
Due to parallel computing, transformers are not able to understand the order of tokens; that is why positional encoding is used, which implants a sequence order via sine or cosine function, giving the model the ability to understand the order of words.
8️⃣ How does scaled dot-product attention actually work?
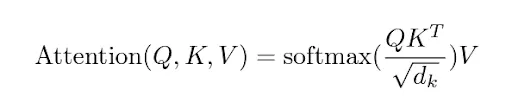
Steps:
- Compute similarity: Q×KTQ \times K^TQ×KT (query × key).
- Scale by dk\sqrt{d_k}dk (dimension of keys) → prevents exploding values.
- Apply softmax → get attention weights.
- Multiply by VVV (values) → weighted sum of information.
This mechanism lets the model focus on the most relevant tokens.
9️⃣ Compare BERT and GPT — where do they shine?
BERT (Bidirectional Encoder): Masked language model trained, therefore, encodes deep bidirectionality. Most effective in knowing how to do things (classification, QA).
GPT (Decoder-only): Autoregressively trained (prediction of next word). Best for generation (story writing, chat, coding).
👉 BERT = understanding. GPT = generation.
🔟 What are some recent advances (e.g., Longformer, Performer, Switch Transformer)?
Longformer: Sparse attention → can deal with very long sequences.
Performer: Approximation based on kernel –> Attention quadratic cost is minimized.
Switch Transformer: Mixture-of-Experts → Only activates portions of the model on a per-input basis and so is highly scalable.
These innovations are efficiency and scalability-oriented and transformers have become more realistic in their practical implementation.
Conclusion
The modern AI depends on transformers. Knowing these 10 questions not only will equip you with preparation to do the interview but also give you insight into the reasons why other systems such as GPT-5 and BERT remain the trendsetters in the field.
Pro tip: Don’t simply memorize: make an attempt to use self-attention in code. Such practical experience differentiates you during interviews.
📬 Want to connect or collaborate? Head over to the Contact page or find me on GitHub or LinkedIn