How RAG Makes AI Smarter: From Chatbots to Research Assistants
Why do we need RAG?
Let me illustrate the need for RAG with a popular example from NVIDIA. Imagine there is a courtroom and judges present there who decide on the cases after hearing, based on the general understanding of law they have, but when there is a complex case, for eg, environmental litigation or medical malpractice, for such scenarios that require special expertise, judges send court clerks to law library where they can find or search for such previous cases from which they can correlate and make decision accordingly.
Here, LLMs are the judges that are capable of answering or solving almost every type of question or query asked by humans, but for problems that require a deep level of knowledge, where court clerks, as Retrieval Augmented Generation, come in play.,
Moreover, RAGs are also very useful in tackling the hallucinations caused by LLMs like GPT, Mistral, etc, and LLMs are limited to the data they are trained on; they can’t answer questions other of their domain.
What is RAG?
Text Generation and Information Retrieval are two processes that RAG combines to form a working system.
- Retrieval: The system accesses pertinent documents on an external knowledge base (such as a search engine or a vector database).
- Generation: The LLM uses the retrieved data to create a factual response to the user query.
The process involves receiving a user’s question, retrieving relevant documents, generating an answer with a language model using those documents, and presenting the response with appropriate citations.
Why is RAG important?
Well, there are some key points where RAG systems have been found to increase efficiency and help in overcoming the limitations of LLMs:
- Lowering Hallucinations: LLMs sometimes hallucinate, which means speaking wrong facts confidently that the user might believe it to be actually true. RAG extracts data directly from research papers using the arXiv API and provides factual results.
- Cost-efficient: Fine-tuning a whole model on a domain-specific task is computationally expensive and time-consuming. RAG helps by just adding the data to your vector database and getting the required information by using a simple chatbot.
- Transparency and Citation: LLMs don’t provide citations of the answers they provide, which is one of the biggest reasons why LLMs are still criticised. RAG provides reference-based answers, eg,” According to this article…”, making them more accurate.
Real-World Applications of RAG
RAG is rapidly evolving multiple industries by providing them with a cost-efficient and simple way. Here are some fields where RAG is dominating:

Research Assistants
Researchers often spend a lot of time analysing and extracting relevant information from various research papers for further usage. With RAG, it’s a lot easier as it can extract papers from arXiv or IEEE, and it can even summarize them and compare their methodologies.
I have built a similar project where I used the arXiv API to fetch the papers, or user can upload their own paper in PDF format and it compares and summarizes the paper for better analysis. You can check it out. [Here]
Enterprise Knowledge Management
Employees working in an organisation often waste much of their time searching for information either online or in emails, etc. RAG provides an instant and accurate response to user queries such as any HR Rules, Legal Lawa, etc. Notion AI and Microsoft Copilot are the best examples of such use cases.
Medical Field
During medical-related work, it’s important to ensure that the data gathered is correct and authenticated, which is why professional uses RAG systems to retrieve data like WHO guidelines, Clinical reports, etc. Suki AI is one of the best examples of an AI-powered healthcare Assistant.
Technical Breakdown of RAG
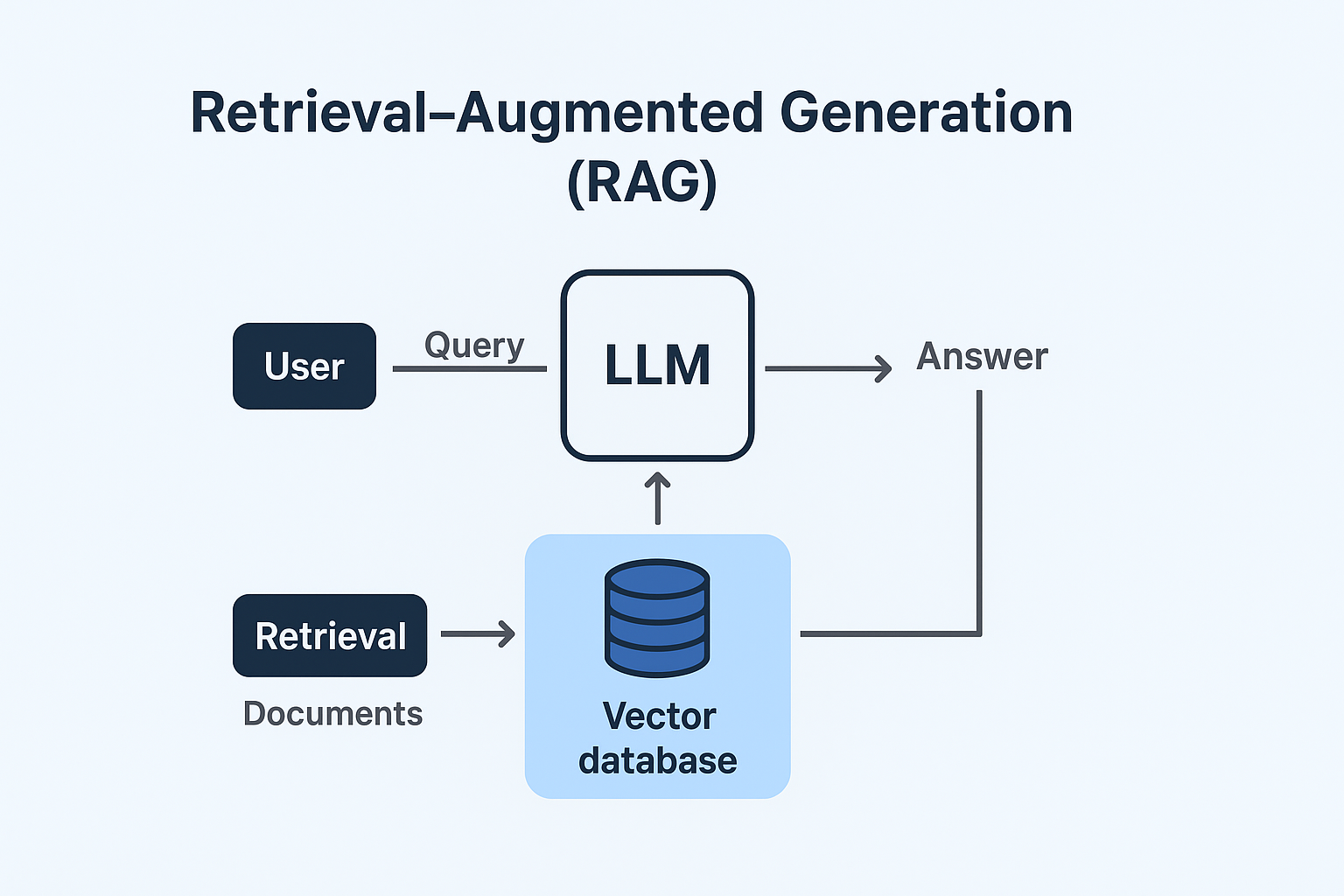
Here’s how a standard RAG pipeline looks and works to solve real-world problems:
- Embedding: Text or documents are transformed into numerical vectors using models such as OpenAI Embeddings or Sentence Transformers.
- Storage: These vectors are stored in vector databases like FAISS, Pinecone, Weaviate, or ChromaDB.
- Retrieval: When a user submits a question, the query is embedded and compared against stored vectors to identify the most relevant documents.
- Generation: The retrieved documents are supplied as context to a large language model (LLM), which generates a factual, contextually relevant answer.
Some tools that are also used while performing above processes for smooth execution:
- – Frameworks: LangChain, LlamaIndex, Haystack
- – Vector Databases: FAISS, Pinecone, Milvus, Weaviate
Limitations
Even RAG has some limitations, which can be troublesome in some cases:
Retrieval Feature
The quality of information provided by the RAG depends on the retrieved data;, there may be cases where the retrieval process may fail, and the LLM may hallucinate or generate inaccurate outputs.
Latency Issues
Fetching the documents from a vector database or uploading the documents and then processing them for generating accurate data may be computationally inefficient, which results in high latency.
Context Window Limitations
There is a specific number of tokens or the number of words an LLM can take or process at a time. This can result which may limit how much context is actually available for generating responses.
Conclusion
All the discussion we had, one thing is clear that RAG can be called the backbone of AI Assistants designed for special tasks.
RAG is already revolutionizing the way we search, learn, and create in settings ranging from corporate boardrooms to research labs, classrooms to clinics. Even though it still has issues with latency, scalability, and retrieval quality, RAG should become even more potent as vector databases, model tuning, and hybrid architectures continue to advance.
RAG is essentially more than just a fad in AI; it is laying the groundwork for the upcoming generation of intelligent assistants and bringing us one step closer to a time when AI is able to think with facts rather than just words.
📬 Want to connect or collaborate? Head over to the Contact page or find me on GitHub or LinkedIn